Optimizing LLM Performance Using Triton
2025-02-22
What is Triton?
- open-source programming language for GPU kernels by Open AI
- Designed for AI/ML workloads
- Simplifies GPU programming compared to CUDA
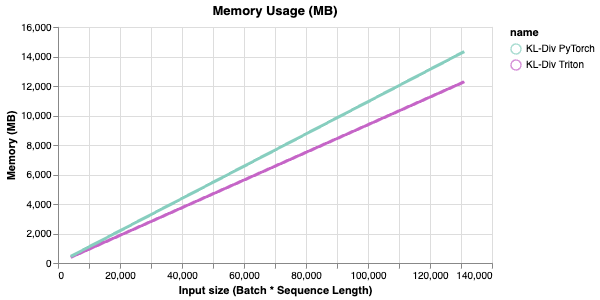
Some benchmarks
- A KL Divergence kernel that is currently used in Liger Kernel written by @me
Do I have to write everything?
- TLDR: No
- Many cool projects already using Triton
- Better Integration with PyTorch and even Hugging Face 🤗
- Liger Kernel, Unsloth AI, etc.


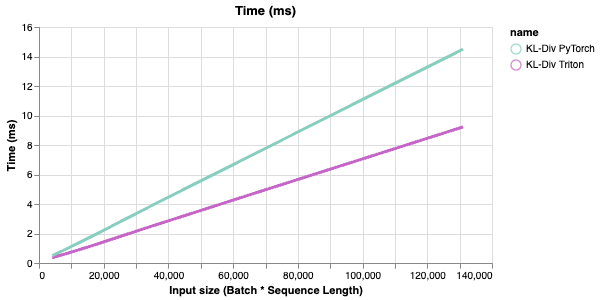
Aaand some more benchmarks 🚀
- Saving memory is key to run bigger batch size on smaller GPUs
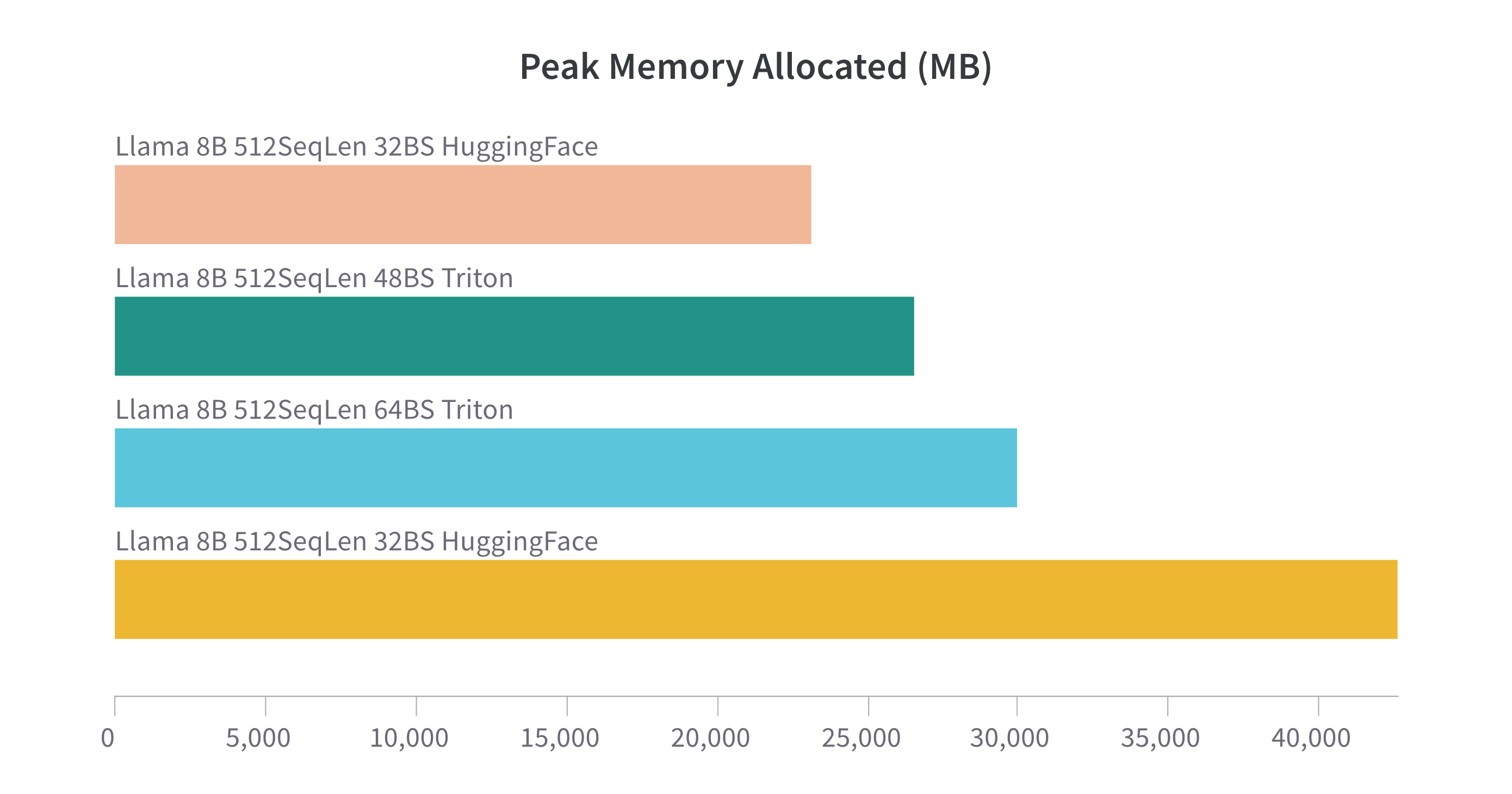
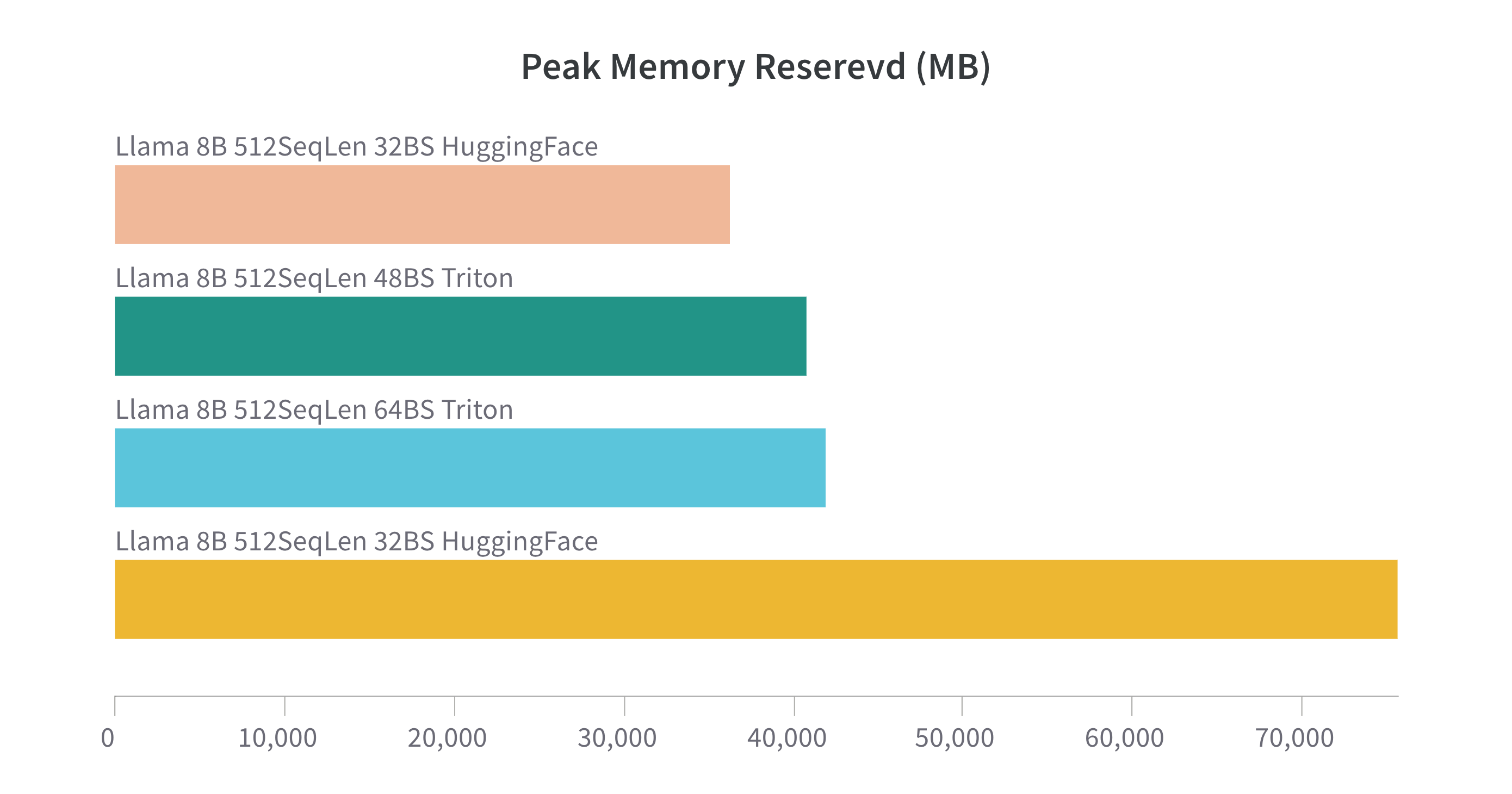
Last benchmark I promise...
- But is it faster? Yes, it is!
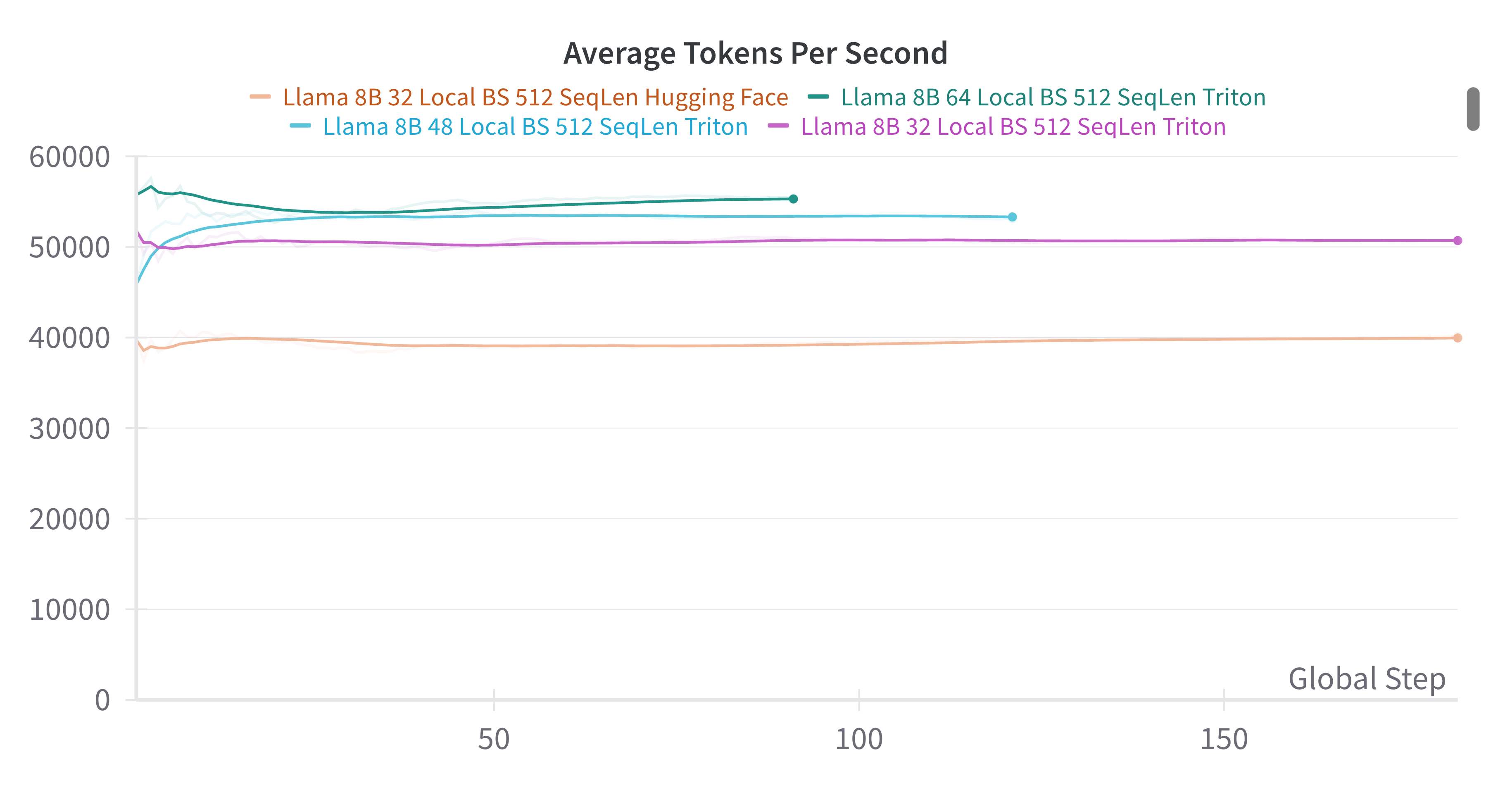
Attention is all you need, so I thank you for yours! 🤗
